K-D-tree
A k-dimensional or k-d tree is a binary tree used to subdivide a collection of records into ranges for k different attributes in each record.
k-d trees are often used as a method of flexible secondary indexing, although there is no reason why primary keys cannot participate as one of the k dimensions.
K-d tree Index
Like any binary tree, k-d tree contains a key and two subtree, left and right. But records are not stored in the internal nodes but in leaf nodes in the form of a collection. where a root-to-leaf path means a condition that every item in the collection meets.
For example, suppose we have these data.

and we have this index tree and stores data in the leaf nodes.
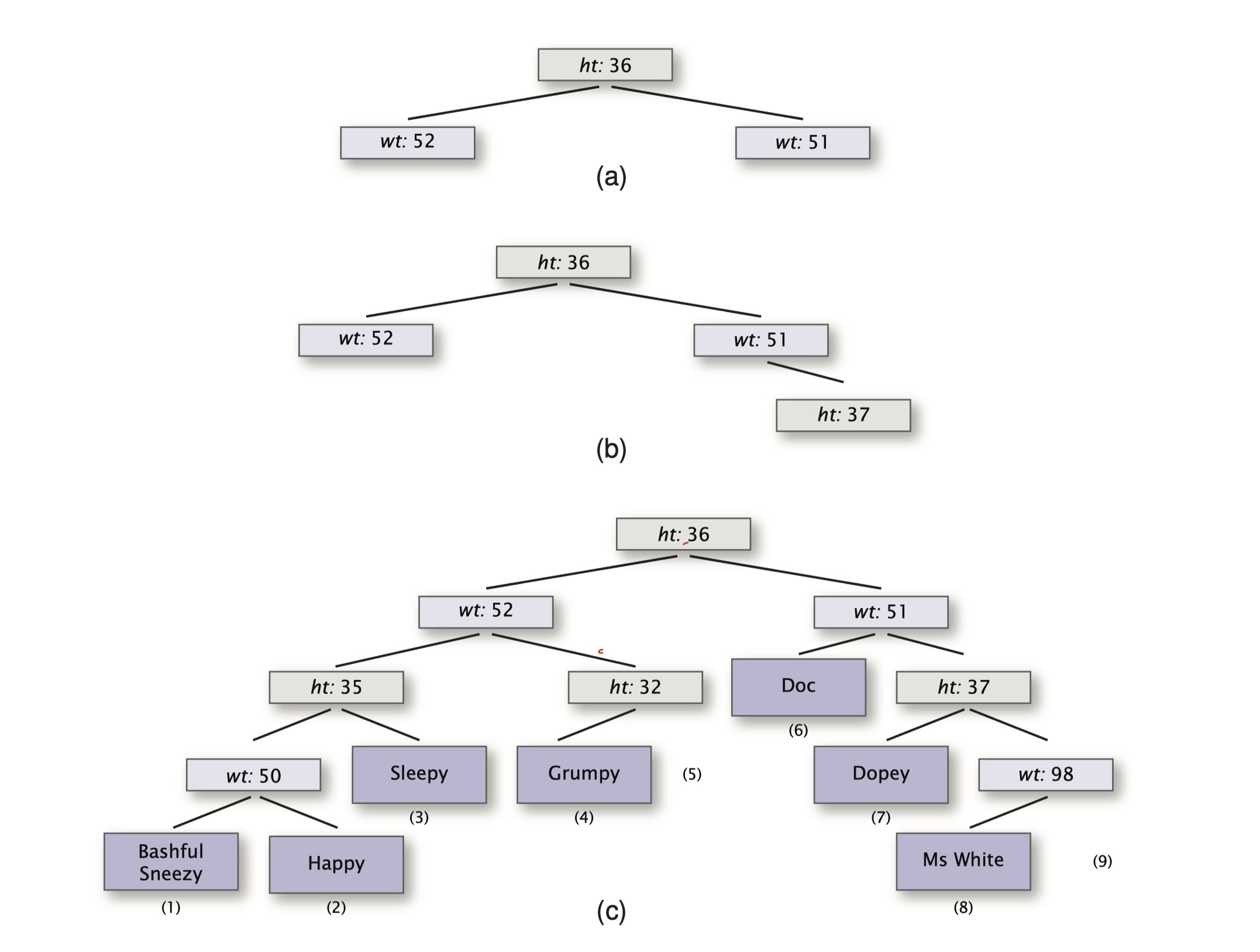
First, we use the given data to build an index tree.
- Insert Sleepy, as the root of the tree, which uses ht as its subdivision attribute.
- Insert Happy. Since Happy’s ht = 34 < 36, so it locates in the left of root. Insert Doc to the right of root. (Figure a)
- Insert Dopey. His ht = 37, so to the right of root, then its wt = 54, to the right of wt=51. (Figure b)
Another way to visualized a k-d tree index is as a subdivision of a k-d space using (k-1)-dimensional cutting plane.

Search
The same as insert.
Performance
We can easily know if the index is balanced, its performance would be better than unbalanced ones. For dynamic trees, maintaining balance in the index is more complicated. Here, adaptive k-d trees can be used to try to adjust the index when buckets become too full or out of balance. A simple, although potentially inefficient, suggestion is to take all the records in an out-of-balance area of the tree, then repartition them and reconstruct the affected region of the index.
Reference
[1] Disk-Based Algorithms for Big Data By Christopher G. Healey